paper · 2026
트랜스포머 XAI를 위한 QKV 분해
가중치만으로 트랜스포머 예측 실패를 진단하고, 한 레이어 재학습으로 교정. GPT-2 수도 정확도 2/8 → 8/8, 부작용 0, V-only Wv 슬라이스(590K params)로도 가능.
What this paper does
This is a reproducible empirical demonstration of surgical correction for routing failures in transformer language models. The work sits within a recent literature on mechanistic interpretability and model editing that has converged on closely related observations:
- Internally encoded knowledge often fails to surface in output — “transformers know but don’t tell” (Liu et al. 2024).
- The final layer suppresses correct predictions through an anti-overconfidence mechanism (Lv et al. 2024).
- Knowledge can be edited at locations beyond MLP, e.g., relation-token weights (Wu et al. 2024 — “Relation Also Knows”).
- Layer-by-layer knowledge circuit tracing is established (Yao et al. 2024 — NeurIPS).
- Architectural variation determines where facts are routed; attention modules in some architectures contribute more than MLP (Choe et al. 2025).
This work contributes a clean specific demonstration on GPT-2 small: targeted retraining of a 590K-parameter Wv slice (0.5% of the model) recovers all 8 capital-city facts with zero measurable side effects on general capability, and publicly released corrected weights enable independent verification.
Applied to GPT-2: factual knowledge (e.g., France→Paris) emerges at layer 10 head 8 (+25.8 logit contribution) and is subsequently reversed at layer 12 head 0 (+149.9 for “the”) — consistent with the anti-overconfidence mechanism reported by Lv et al. Targeted retraining of only the diagnosed layer recovers knowledge accuracy from 2/8 to 8/8 capitals with zero side effects (general capability 11/15 maintained, PPL 42.7 → 42.6).
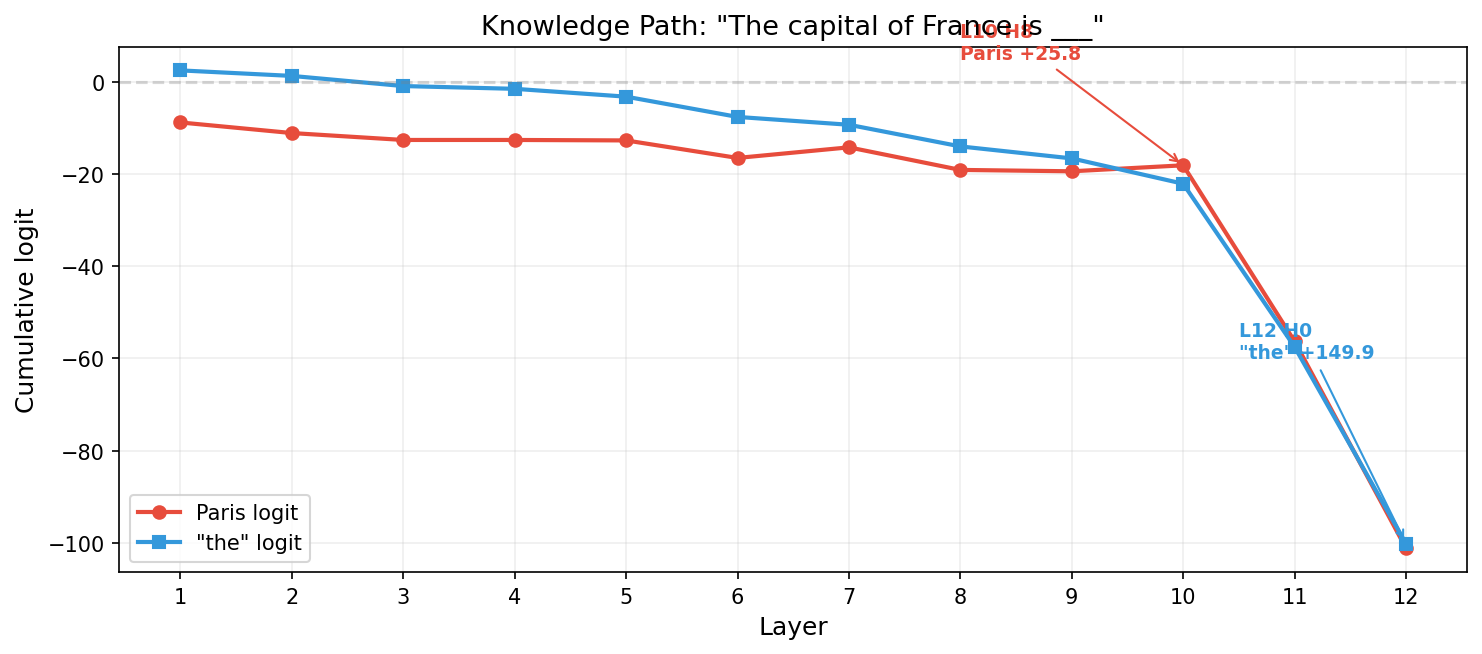
The model already possesses this knowledge internally; the failure is one of routing, not absence.

Why it matters
Routing correction can be achieved through attention V, FFN, or even V-only (Wv slice, 590K parameters — 0.5% of GPT-2). This is consistent with the broader observation that knowledge routing is not confined to FFN layers (Wu et al. 2024; Choe et al. 2025), and adds quantitative specificity: a 590K-parameter modification suffices, well below the parameter footprint of standard MLP-edit methods. The result clarifies that methods restricting edits to MLP layers (e.g., ROME) target storage — appropriate for knowledge insertion, but unnecessarily narrow when the underlying failure is routing.
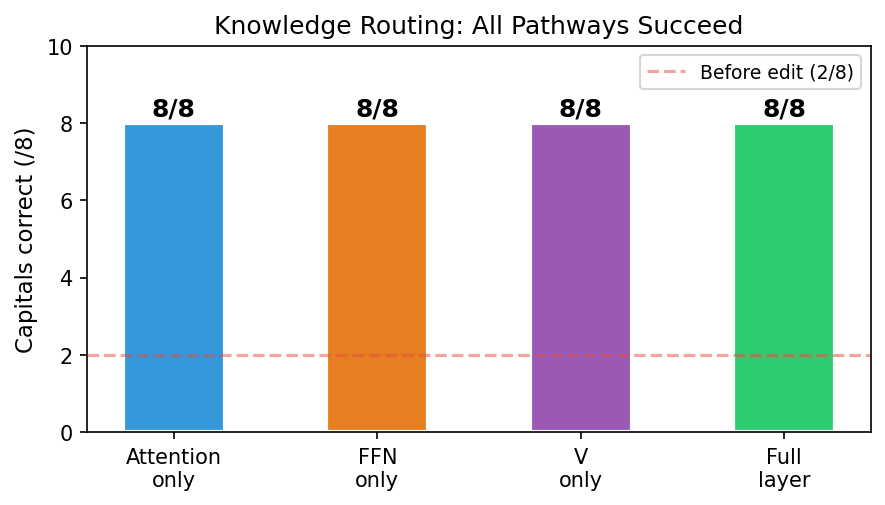
This opens correction pathways beyond MLP-only model editing.
What’s specifically new here
Component-level findings (routing failures, late-layer suppression, non-MLP editability) sit within the recent literature cited above. What this work adds:
-
Head-to-head comparison of four correction pathways under identical evaluation — full L10 layer (7.1M params) vs. attention only (2.4M) vs. FFN only (4.7M) vs. V-only Wv slice (590K). All four reach 8/8 with zero side effects; 590K (0.48% of GPT-2) is identified as the minimum sufficient scale. Prior work proposes single-site edits without systematic cross-pathway comparison.
-
Combined static (input-free) and dynamic (per-input) diagnosis feeding the same prescription target — input-free Q/K/V weight classification of all 144 heads (Section: Static diagnostics) together with per-input logit-trace decomposition jointly identifying L10 as the correction site. Prior work typically uses one diagnostic mode in isolation.
-
End-to-end public artifact set — diagnosis scripts, corrected GPT-2 weights at four parameter scales, an interactive head dashboard, and tri-tool cross-validation outputs publicly released for independent verification.
-
Side-effect protocol with 25 held-out probes — separating general capability (15 probes) from unrelated tasks (10 probes), providing finer-grained side-effect measurement than aggregate perplexity drawdown alone.
The integration is the contribution, not any single component.
Static diagnostics (input-free)
The method also classifies all 144 attention heads in GPT-2 small directly from weights — no input pass required:
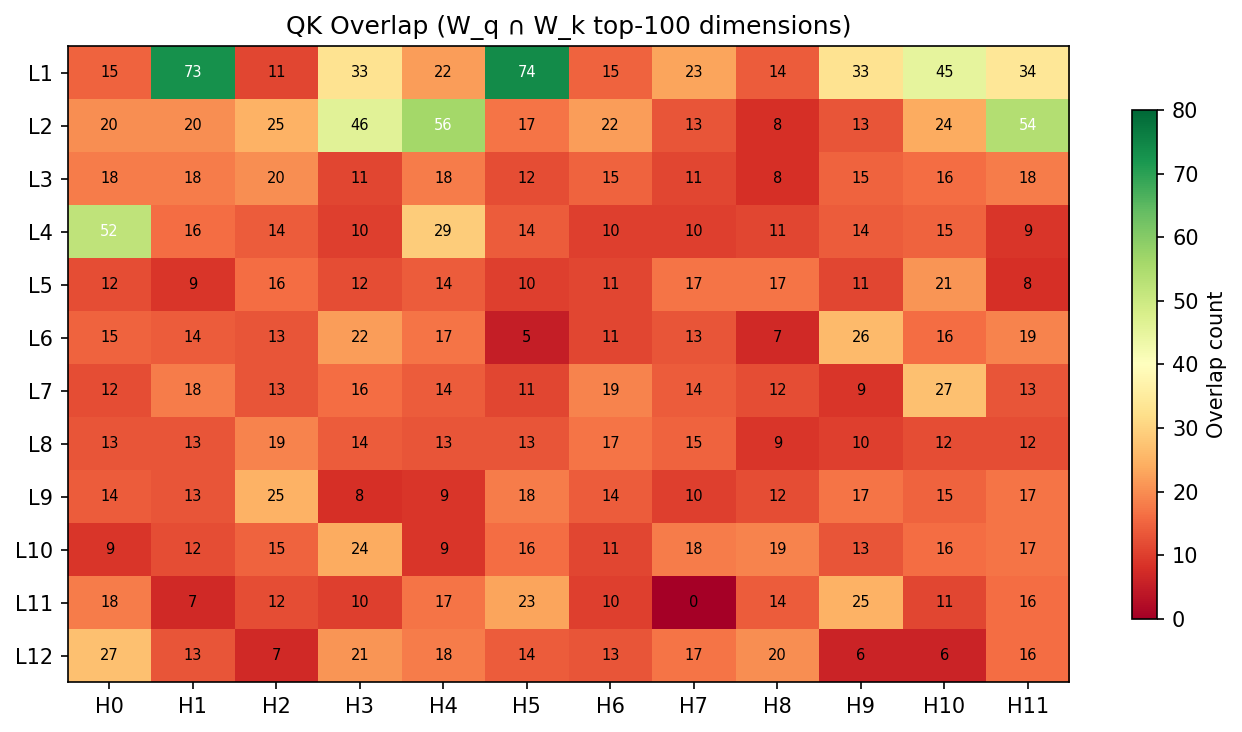
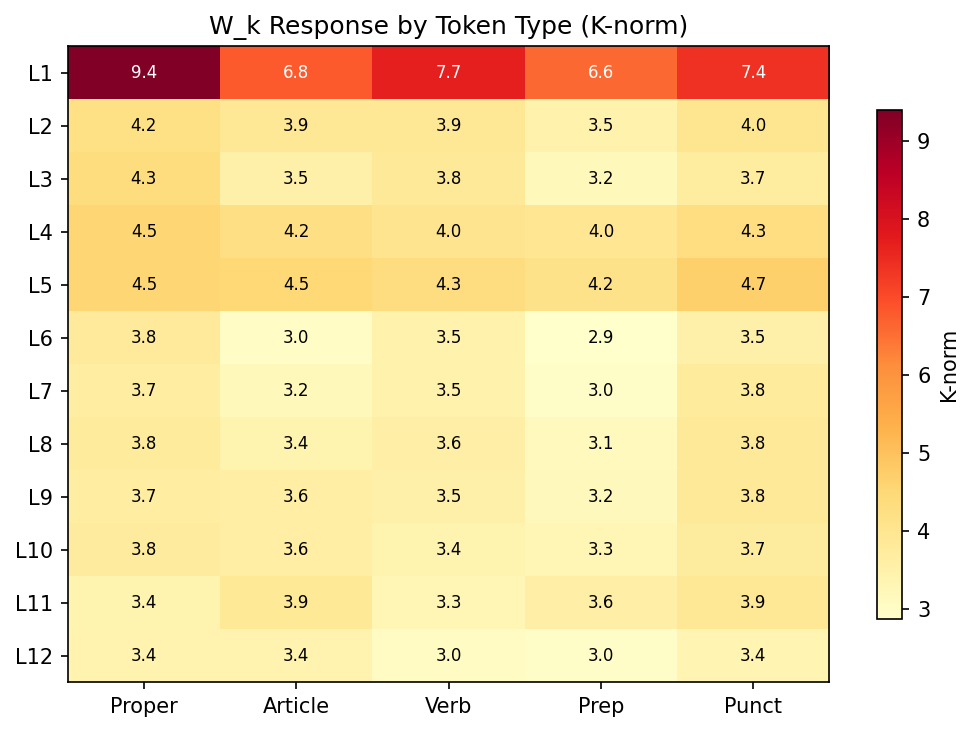
Cross-validation
- Captum (gradient × activation): top-1 neuron agreement (n=2440)
- TransformerLens logit lens: same routing layer identified
- Activation patching: confirms causal involvement (-0.44 logit when neuron zeroed)
Verify
- Zenodo — paper PDF + permanent DOI for citation.
- HuggingFace dashboard — corrected GPT-2 L10 weights, QKV analysis scripts, interactive dashboard, all figures. Anyone can re-run the 8 capital-city prompts and check.
arXiv preprint: forthcoming.