paper · 2026
트랜스포머 XAI를 위한 QKV 분해
가중치만으로 트랜스포머 예측 실패를 진단하고, 한 레이어 재학습으로 교정. GPT-2 수도 정확도 2/8 → 8/8, 부작용 0, V-only Wv 슬라이스(59만 params)로도 가능.
이 논문이 한 일
이 작업은 트랜스포머 언어 모델의 라우팅 실패 를 외과적으로 교정하는 재현 가능한 실증 입니다. 이 작업은 mechanistic interpretability 및 model editing 분야의 최근 관찰들과 인접해 있습니다:
- 내부에 인코딩된 지식이 출력으로 나오지 못하는 현상 — “transformers know but don’t tell” (Liu et al. 2024)
- 마지막 레이어가 정답 예측을 억제하는 anti-overconfidence 메커니즘 (Lv et al. 2024)
- MLP 이외 위치에서의 편집 가능성 (예: relation-token weights, Wu et al. 2024 — “Relation Also Knows”)
- 레이어 단위 knowledge circuit 추적 (Yao et al. 2024 — NeurIPS)
- 아키텍처 차이가 사실 라우팅 위치를 결정 — 일부 아키텍처에서는 attention 이 MLP 보다 더 기여 (Choe et al. 2025)
이 작업의 contribution은 GPT-2 small 위에서의 깨끗한 specific 실증 입니다: 59만 파라미터 Wv slice (모델의 0.5%) 만 재학습해서 8개 수도 정답 모두 회복, 일반 능력에 측정 가능한 부작용 0, 그리고 공개된 수정 가중치로 독립적 검증 가능.
GPT-2 에 적용: 사실 지식 (예: France → Paris) 이 layer 10 head 8 에서 emerge 하고 (+25.8 logit 기여), 두 레이어 뒤 layer 12 head 0 에서 반전됩니다 (+149.9, “the” 쪽) — Lv et al. 의 anti-overconfidence 메커니즘 관찰과 일관. 진단된 레이어만 재학습해서 수도 정확도를 2/8 → 8/8 회복, 부작용 0 (일반 능력 11/15 유지, PPL 42.7 → 42.6).
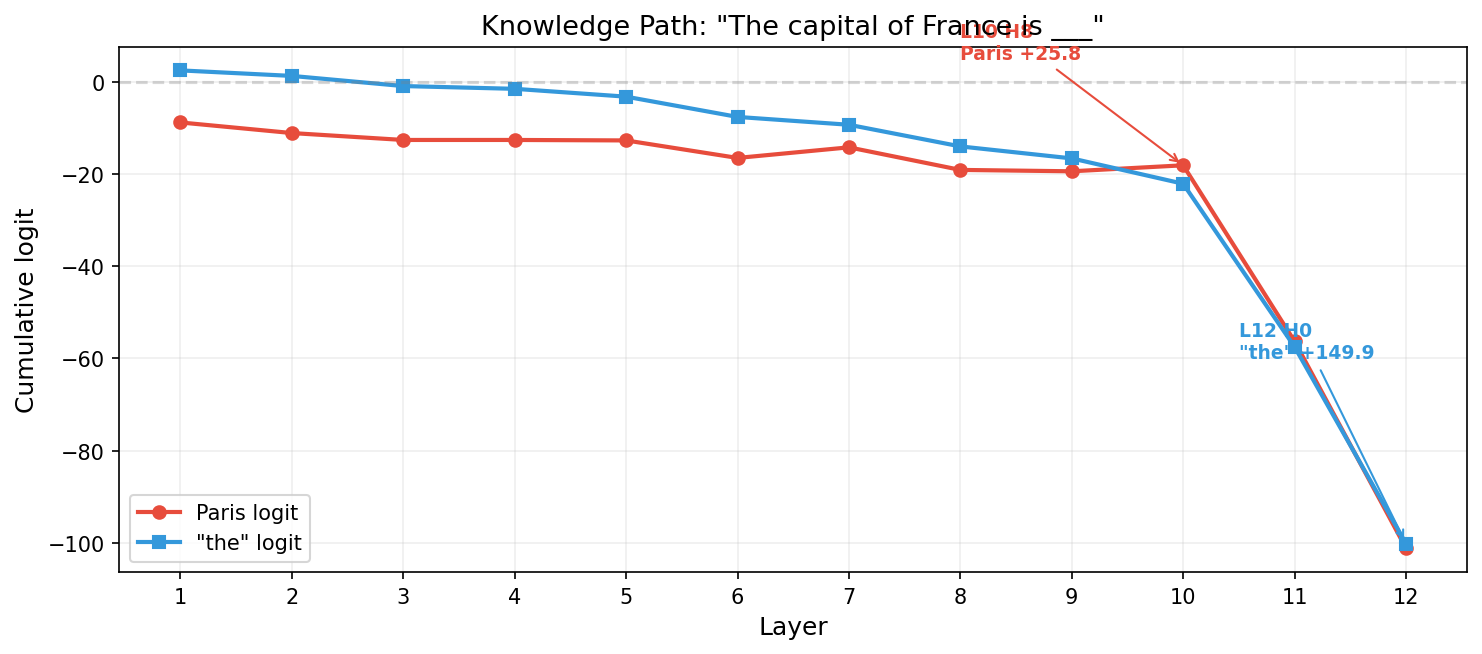
모델은 이미 그 지식을 내부에 가지고 있었습니다. 실패는 지식 부재가 아니라 라우팅 실패.

왜 중요한가
라우팅 교정은 attention V · FFN · 심지어 V-only (Wv slice, 59만 파라미터 — GPT-2 의 0.5%) 어디서든 가능합니다. 이는 지식 라우팅이 FFN 레이어에 한정되지 않는다 는 더 넓은 관찰 (Wu et al. 2024; Choe et al. 2025) 과 일관되며, 정량적 specific 을 추가합니다 — 59만 파라미터 수정만으로 충분, 표준 MLP-edit 방법의 파라미터 footprint 보다 훨씬 작음. 결과적으로, MLP 만 편집하는 방법 (ROME 등) 은 storage 교정 — 지식 삽입에는 적합하지만 routing 실패 에는 불필요하게 좁아짐을 확인.
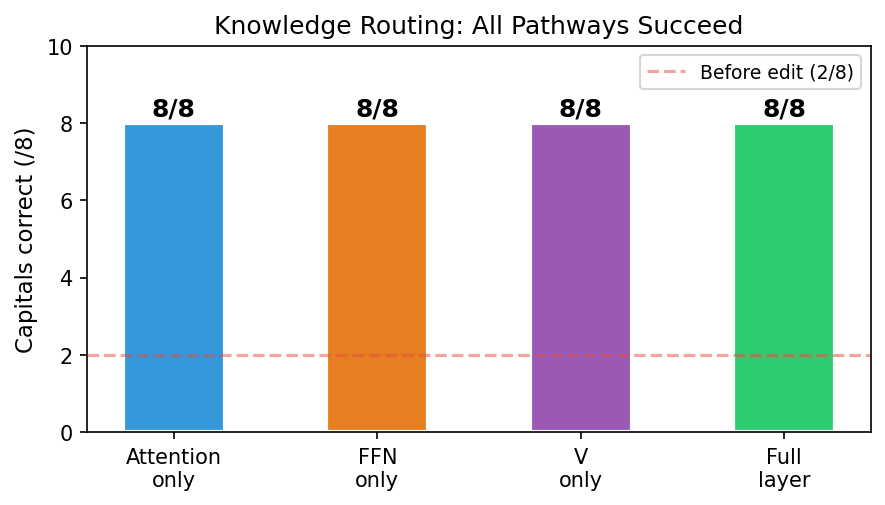
이게 MLP 만 편집하는 model editing 의 좁은 가정을 깨고, 교정 경로를 4배 확장합니다.
이 작업이 가지는 specific contribution
Component-level finding (routing failure, 마지막 레이어 suppression, MLP 외 edit 가능성) 들은 위 인용 priors 안에 이미 있습니다. 이 작업이 추가하는 것:
-
4가지 correction pathway 의 head-to-head 정량 비교 — 동일 평가 기준 하: full L10 layer (7.1M params) / attention only (2.4M) / FFN only (4.7M) / V-only Wv slice (59만). 네 가지 모두 8/8 도달, 부작용 0. 59만 (GPT-2 의 0.48%) 이 최소 충분 파라미터 규모로 식별. Priors 는 single-site edit 만 제안, cross-pathway 체계적 비교 는 없음.
-
Static (input-free) + Dynamic (per-input) 진단 통합 → 같은 prescription target — 144 attention head 의 Q/K/V 가중치 분류 (입력 없이; Static 진단 섹션 참조) 와 per-input logit trace 분해 가 함께 L10 을 교정 site 로 지목. Priors 는 보통 하나의 진단 모드 만 단독 사용.
-
End-to-end 공개 artifact 세트 — 진단 script, 4가지 parameter scale 의 수정된 GPT-2 가중치, interactive head dashboard, tri-tool cross-validation 결과를 모두 공개 — 독립 검증 가능.
-
Side-effect 25-probe 프로토콜 — 일반 능력 (15 probe) 과 무관 task (10 probe) 를 분리 측정, 단순 PPL drawdown 통합 측정보다 더 세밀한 부작용 측정 제공.
Integration 자체가 contribution — single component novelty 가 아님.
Static 진단 (입력 없이)
이 방법은 144 개 GPT-2 small attention head 를 가중치만으로 분류할 수 있습니다 — 입력 forward pass 불필요:
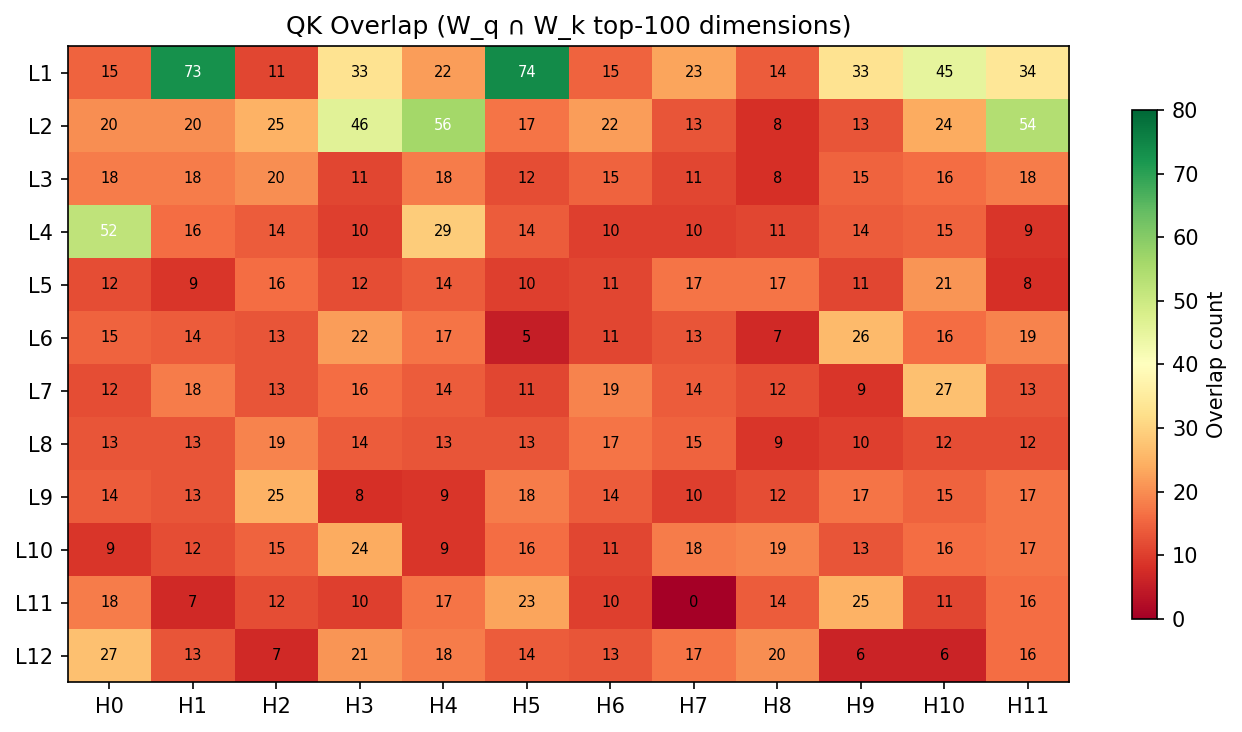
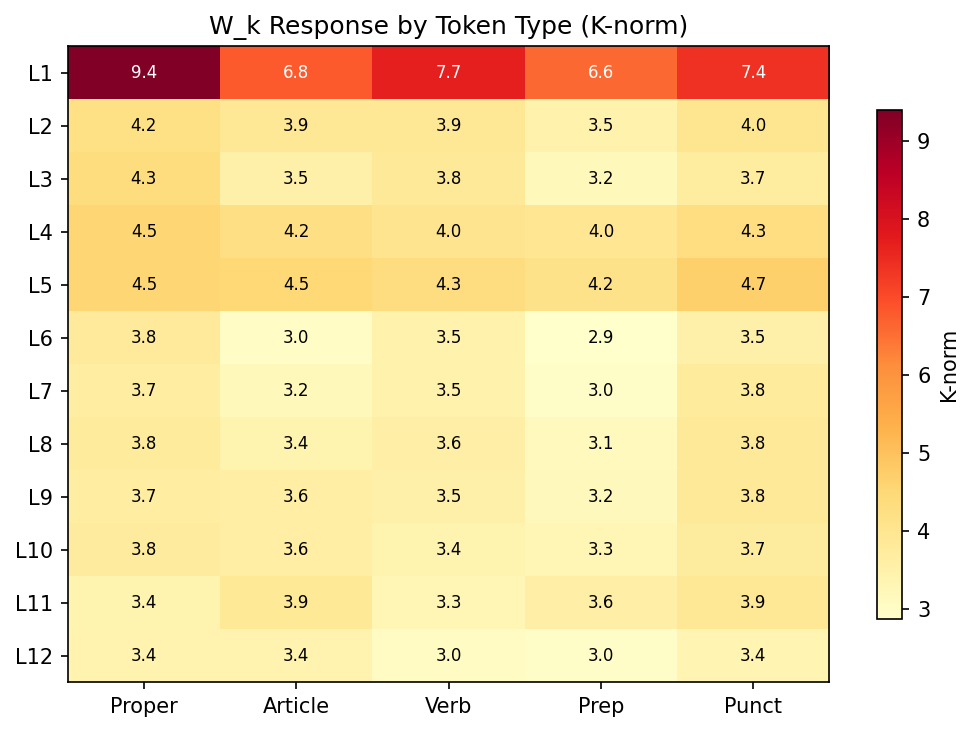
교차 검증
- Captum (gradient × activation): top-1 neuron 일치 (n=2440)
- TransformerLens logit lens: 같은 라우팅 layer 식별
- Activation patching: 인과적 관여 확인 (neuron zero-out 시 logit −0.44)
검증
- Zenodo — paper PDF + 영구 DOI (citation 가능)
- HuggingFace dashboard — 교정된 GPT-2 L10 가중치, QKV 분석 script, interactive dashboard, 모든 figure. 누구나 8개 수도 prompt 직접 실행해서 검증 가능.
arXiv preprint: 진행 예정.