2026-05-10
Deep learning is editable
We treat a deep neural network as something you train, not something you fix.
When a model answers wrong, the default repair is more data, more compute, more passes. Fine-tuning. RLHF. A new run. The unit of change is always a training run; the assumed cost is always large.
This is a habit, not a fact. Some of what looks broken in a trained network can be repaired surgically — by changing a small number of parameters, in a precise location, in a single pass, without damaging anything else.
Here is the demonstration.
A model that knew but wouldn’t say so
GPT-2 small. 124 million parameters. Ask it:
The capital of France is ___
It answers “the”.
Six of eight capital-city facts come back wrong: France, Japan, Germany, China, Russia, England. Italy and Spain it gets right. By any normal reading, the model just doesn’t know enough.
Now trace what happens layer by layer:
| Layer | Head | Paris logit | ”the” logit | What happens |
|---|---|---|---|---|
| L1–L6 | (all) | −16.5 | −7.6 | No Paris signal |
| L7 | H4 | +3.1 | −0.2 | Paris first emerges |
| L10 | H8 | +25.8 | −2.8 | Paris signal strong |
| L11 | H0 | +11.2 | −1.6 | Reinforced |
| L12 | H0 | −29.3 | +149.9 | ”the” overrides everything |
| Final | −101.2 | −100.2 | ”the” wins by 1.0 |
The model knows. By layer 10, Paris has a strong positive contribution. Then layer 12 head 0 — a head specialized on starting noun phrases with “the” — fires with overwhelming force and reverses everything. Paris loses by about one logit.
This is a routing failure, not a knowledge failure. The information existed inside the network. The path from where it was held to where it came out broke at the last step.
The surgery
If the failure is routing, you don’t need new knowledge. You need to strengthen the existing signal so it survives the downstream override.
Train only L10. One epoch. Targeted loss on the answer. Output-matching loss on unrelated data to preserve general capability.
| Metric | Before | After | Δ |
|---|---|---|---|
| Capitals correct | 2 / 8 | 8 / 8 | +6 |
| General capability | 11 / 15 | 11 / 15 | 0 |
| Side-effect panel | 2 / 10 | 2 / 10 | 0 |
| Perplexity | 42.7 | 42.6 | −0.1 |

All six wrong capitals fixed. Nothing else damaged. The model now answers Paris, Tokyo, Berlin, Beijing, Moscow, London — and still parses sentences, still completes prompts, still does whatever it did before.
The detail that made me re-check the experiment three times
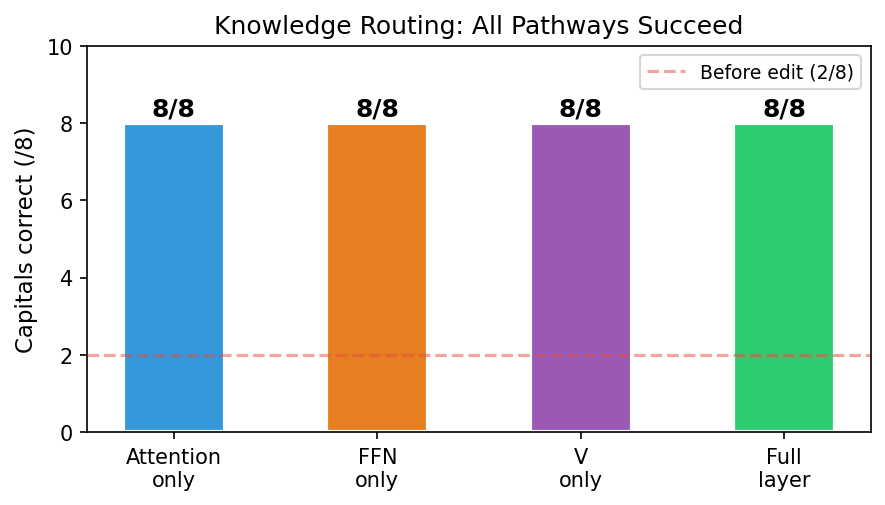
L10 has 7.1 million parameters. You don’t need to touch all of them.
| What gets trained | Parameters | Result |
|---|---|---|
| Full L10 layer | 7.1M | 8/8 |
| Attention only (FFN frozen) | 2.4M | 8/8 |
| FFN only (attention frozen) | 4.7M | 8/8 |
| Wv slice only (Q, K, FFN all frozen) | 590K | 8/8 |
The Wv slice is the value projection — c_attn.weight[:, 1536:2304] — a 768×768 matrix. 590,000 parameters. Half a percent of the model. Q and K weights are gradient-masked to zero, verified unchanged. ΔL2 of the modified slice is 4.83; max element-wise change is 0.027.
That’s the surgery. 0.5% of the network, modified once, fixes all eight failures with zero collateral.
What this is not
Not knowledge insertion. The model already had the knowledge — the L10 H8 trace shows it carrying the Paris signal at +25.8. The surgery fixes the path, not the data. For genuinely absent knowledge, this approach doesn’t apply; you’d need a different intervention.
Not a scaling claim. This was GPT-2 small. Whether the same surgical pattern works at Llama-7B or larger is the next question, not the current one. The routing-vs-storage distinction has no obvious reason to break at scale, but no obvious proof either, until it’s tested.
Not magic. The fix only works because the diagnosis was correct. Without identifying L10 as the routing bottleneck — which required tracing layer-by-layer logit contributions — there is no targeted edit. The intervention is small because the diagnosis was specific.
Others have been showing this from multiple angles
This isn’t a private observation. Several lines of mechanistic interpretability research have converged on related findings:
- Knowledge held but not surfaced. Liu et al. 2024 — transformers internally encode facts that don’t reach the output.
- Late-layer suppression. Lv et al. 2024 — the final layer’s anti-overconfidence mechanism actively suppresses correct predictions.
- Routing extends beyond MLP. Wu et al. 2024 — knowledge edits can target locations other than FFN, including relation-token weights.
- Knowledge circuits. Yao et al. 2024 (NeurIPS) — attention and MLP cooperate in fact retrieval through identifiable subgraphs.
- Copy suppression. McDougall et al. 2024 — specific attention heads suppress repeated tokens, a mechanism related to the L12 H0 reversal seen here.
- Ripple effects, and direct edit methods. Cohen et al. 2024 measures the downstream effects of fact-level edits; ROME, MEMIT, PISCES, EasyEdit provide rank-1 MLP edits, batch edits, SAE-based erasure, and integration toolkits.
The mechanism is real and the field has demonstrated it from many angles. None of the core observations in this essay are first discoveries on my part.
What I’m trying to add — an integrated practical pipeline across architectures
Where prior work tends to show one piece per paper, an operator needs a complete pipeline: diagnose, decide where to edit, perform the edit, verify side effects, track cascades, release the result. I’ve been trying to build that — and to show it works across architectures, not just within LLMs:
- GPT-2 small (decoder transformer). The running example above. A 590K-parameter Wv slice — 0.5% of the model — fixes six wrong capital-city answers, zero side effects, four pathway variants compared head-to-head.
- BERT (encoder transformer). Five GLUE tasks. Separability-guided layer skip with a small compensation classifier yields lossless compression on 3 of 5 tasks. FFN decomposes as 92% structural (norm normalization) and 8% classification — explaining why per-layer FFN looks harmful yet is structurally load-bearing. 60–93% of misclassifications are confidently wrong — the CLS vector itself points the wrong way.
- CheXNet (medical CNN, DenseNet121). Chest X-ray classifier compressed 51% (6.97M → 3.38M parameters) at constant accuracy. Channel-level surgical correction: a 5-channel zero-out reduces a target false positive by Δprob −0.13 with zero true-positive loss and exactly zero AUROC change on the other 13 pathologies.
The contribution isn’t a new mechanism. It’s the pipeline that makes existing mechanisms usable — read the weights, trace what each piece does, find the smallest sufficient edit, verify side effects, release reproducible artifacts.
The implementation unit varies — heads vs. layers vs. channels. The operational unit stays the same: a precise change, applied once, with verifiable evidence.
What it changes
The dominant model of repair in deep learning is more training. Models drift, get fine-tuned, get aligned, get merged, get continually pre-trained. The unit of change is always a training run.
Surgical editing offers a different unit: a precise change, in a precise location, applied once, with no collateral.
This isn’t a replacement for training. It’s a complement, with a clear domain of application:
- When the failure is routing — the system has the answer but emits the wrong one — surgery is the right tool.
- When the failure is genuine absence — the system never had the answer — training is the right tool.
- When the failure is alignment — the system has the wrong objective — surgery is probably not the right tool, but the routing question may be worth asking before assuming retraining.
The first job is to distinguish these. That’s what the diagnostic side of the work is for. Read the weights to see what each head can do; trace the per-input logits to see what each head actually did; identify where the signal that should win is being overridden.
If this generalizes — and the underlying distinction between holding information and transmitting it holds at any scale — then model maintenance starts to look very different. Not “retrain when it drifts” but “diagnose the failure, edit the layer, ship the fix.”
That is a different operational discipline. It’s closer to surgery than to gardening.
What I’m sure of, and what I’m not
I’m sure: on GPT-2 small, with the diagnostic method described, six wrong capital-city answers can be made correct by editing 590,000 parameters. General capability and side-effect panels are unchanged within measurement noise. The corrected weights are public for anyone to verify.
I’m not yet sure: how broad the routing-vs-storage distinction is in modern LLMs. How many real-world failures are routing failures versus knowledge absences. How small the edits stay as models scale. Whether the diagnostic method automates cleanly to thousands of facts.
These are the questions worth asking next. The first answer — that surgery is even possible — is in.
Source: paper9 — QKV Decomposition for Transformer XAI. Zenodo · HuggingFace (corrected weights + dashboard).