2026-05-10
딥러닝은 외과수술이 가능하다
신경망은 학습시키는 것이지, 고치는 것이 아니다. 우리는 보통 그렇게 생각한다.
답이 틀리면 더 학습. 값이 어긋나면 더 학습. 행동이 이상해도 더 학습. 수리의 도구는 항상 더 많은 데이터와 더 많은 계산이고, 변경의 단위는 늘 학습 한 번이며, 비용도 항상 크다고 가정된다.
이건 사실이라기보다 습관이다. 학습된 신경망에서 망가져 보이는 것 가운데 일부는 외과적으로 고칠 수 있다. 정확한 자리의 적은 파라미터를, 단 한 번의 패스로, 다른 어떤 것도 건드리지 않고.
한 사례를 보자.
알면서도 말하지 않는 모델
GPT-2 small. 1억 2,400만 파라미터. 이렇게 묻는다.
프랑스의 수도는 ___
답은 “the”.
여덟 나라의 수도 가운데 여섯 개를 틀린다. 프랑스, 일본, 독일, 중국, 러시아, 영국. 이탈리아와 스페인만 맞춘다. 보통이라면 *“이 모델은 잘 모르는구나”*로 끝나는 자리다.
그런데 신경망 안을 레이어 단위로 따라가 보면 이야기가 달라진다.
| 레이어 | 헤드 | Paris logit | ”the” logit | 일어나는 일 |
|---|---|---|---|---|
| L1–L6 | (전체) | −16.5 | −7.6 | Paris 신호 없음 |
| L7 | H4 | +3.1 | −0.2 | Paris가 처음 등장 |
| L10 | H8 | +25.8 | −2.8 | Paris 신호가 자리 잡음 |
| L11 | H0 | +11.2 | −1.6 | 신호 보강 |
| L12 | H0 | −29.3 | +149.9 | ”the”가 모든 걸 뒤집음 |
| 최종 | −101.2 | −100.2 | ”the”가 1.0 차이로 승 |
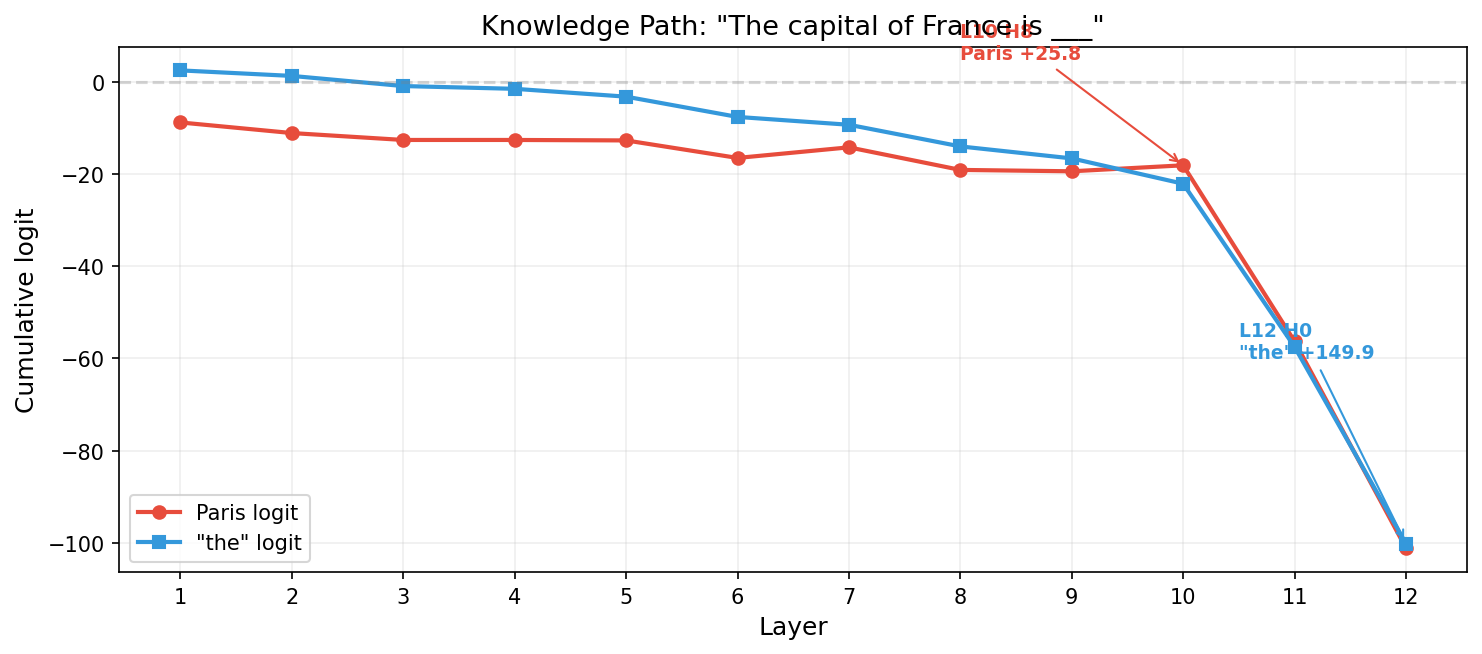
L10 시점에서 Paris는 이미 +25.8로 뚜렷하게 잡혀 있다. 모델은 알고 있다. 두 레이어 뒤, 명사구를 “the”로 시작하는 데 특화된 한 헤드(L12 H0)가 등장한다. 이 녀석이 +149.9라는 압도적인 힘으로 그동안의 모든 신호를 뒤집어 버린다. Paris는 약 1.0 차이로 밀린다.
이건 라우팅 실패다. 지식이 없는 게 아니다. 답은 모델 안에 있었고, 그 답이 머무는 자리에서 출력으로 나가는 경로가 마지막 단계에서 끊긴 것뿐이다.
외과수술
라우팅이 문제라면 새로운 지식을 더할 필요가 없다. 이미 있는 신호가 뒤쪽의 덮어쓰기를 살아남도록 더 강하게 만들면 된다.
L10만 학습한다. 한 epoch. 정답을 향한 targeted loss. 무관한 데이터에는 output-matching loss로 일반 능력을 보존한다.
| 지표 | 전 | 후 | Δ |
|---|---|---|---|
| 수도 정답 | 2 / 8 | 8 / 8 | +6 |
| 일반 능력 | 11 / 15 | 11 / 15 | 0 |
| 부작용 패널 | 2 / 10 | 2 / 10 | 0 |
| Perplexity | 42.7 | 42.6 | −0.1 |

여섯 개가 전부 정답으로 바뀐다. 다른 어떤 것도 손상되지 않는다. 모델은 이제 Paris, Tokyo, Berlin, Beijing, Moscow, London을 답한다. 동시에 문장을 파싱하고, 프롬프트를 완성하고, 그전에 하던 일을 그대로 한다.
세 번 다시 확인하게 만든 디테일
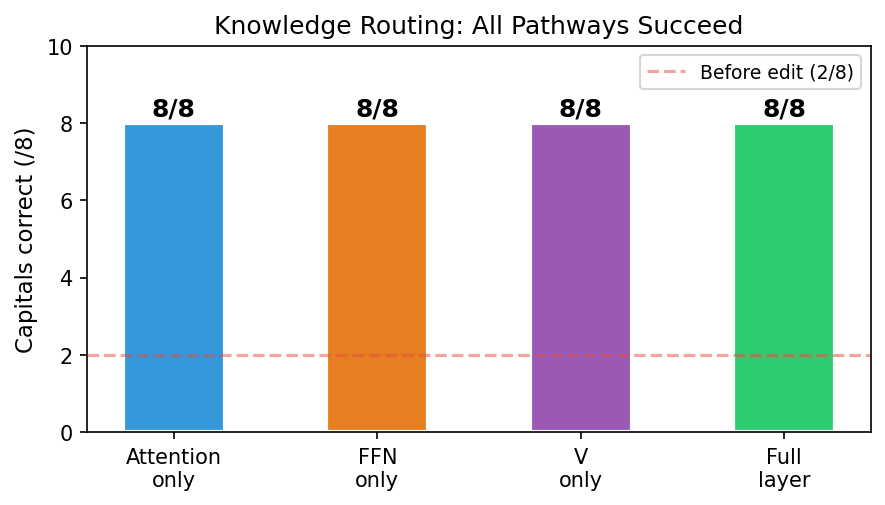
L10에는 710만 파라미터가 있다. 그 전부를 만질 필요는 없다.
| 학습 대상 | 파라미터 | 결과 |
|---|---|---|
| L10 전체 | 7.1M | 8/8 |
| Attention만 (FFN 동결) | 2.4M | 8/8 |
| FFN만 (Attention 동결) | 4.7M | 8/8 |
| Wv slice만 (Q, K, FFN 모두 동결) | 590K | 8/8 |
Wv slice는 value projection이다. c_attn.weight[:, 1536:2304] — 768×768 행렬. 59만 파라미터. 모델의 0.5%. Q와 K는 gradient-mask로 묶어 변경 없음을 확인했다. 수정된 slice의 ΔL2는 4.83, 가장 큰 변화도 0.027에 그친다.
이게 외과수술의 실제 모습이다. 모델의 0.5%를 한 번 손봐서, 여덟 개의 실패를 모두 바로잡는다. 다른 곳에 흠집 하나 없이.
이게 아닌 것
지식을 새로 넣는 게 아니다. 모델은 이미 그 지식을 갖고 있었다. L10 H8가 Paris를 +25.8로 운반하는 장면이 그 증거다. 외과수술은 경로를 고칠 뿐, 데이터를 고치지 않는다. 모델이 정말로 모르는 사실이라면 다른 방법이 필요하다.
스케일 주장도 아니다. 이건 GPT-2 small이다. Llama-7B 정도, 혹은 그 이상에서 같은 패턴이 작동할지는 다음에 답해야 할 질문이지 지금 답해진 질문이 아니다. 라우팅과 저장의 구분이 큰 모델에서 갑자기 깨질 만한 이유는 보이지 않지만, 검증되기 전까지 보장되는 것은 아무것도 없다.
마법도 아니다. 진단이 정확했기 때문에 작동한 것이다. L10이 라우팅 병목이라는 사실 — 레이어별 logit을 따라가서 얻어낸 결론 — 없이는 정확한 편집 자체가 불가능하다. 개입이 작은 이유는 진단이 구체적이었기 때문이다.
다른 분들이 여러 각도에서 보여주고 있다
이건 혼자만의 관찰이 아니다. mechanistic interpretability 분야의 여러 연구가 비슷한 자리에 수렴해 왔다.
- 알면서도 출력 못 함. Liu et al. 2024 — 트랜스포머가 내부에는 사실을 가지고 있는데 출력으로 못 내보내는 현상.
- 마지막 레이어의 억제. Lv et al. 2024 — 최종 레이어의 anti-overconfidence 메커니즘이 정답을 적극적으로 억제한다.
- 라우팅은 MLP 한정이 아님. Wu et al. 2024 — relation-token 가중치 같은 비-FFN 위치에서도 지식 편집이 가능하다.
- 지식 회로. Yao et al. 2024 (NeurIPS) — attention과 MLP가 식별 가능한 subgraph에서 협력해 사실을 검색한다.
- Copy suppression. McDougall et al. 2024 — 특정 attention head가 반복 토큰을 억제하는 메커니즘. 위에서 본 L12 H0 reversal과 관련 있다.
- 파급 효과와 직접 편집. Cohen et al. 2024는 사실 단위 편집의 downstream 영향을 측정한다. ROME, MEMIT, PISCES, EasyEdit은 rank-1 MLP 편집, batch 편집, SAE 기반 erasure, 통합 toolkit을 제공한다.
메커니즘은 실재하고, 분야는 그것을 여러 각도에서 입증해 왔다. 이 글에서 다룬 핵심 관찰 가운데 어느 것도 내가 처음 발견했다고 주장하는 것이 아니다.
내가 더하려는 것 — 아키텍처를 가로지르는 실무 통합 파이프라인
선행 연구들이 한 논문에 한 조각씩 보여준다면, 실제 운영하는 입장에서는 완결된 파이프라인이 필요하다 — 진단하고, 어디를 편집할지 결정하고, 실제로 편집하고, 부작용을 검증하고, 파급(cascade)을 추적하고, 결과를 공개한다. 나는 이 파이프라인을 만들려고 해왔고, LLM 한 종류 안이 아니라 아키텍처를 가로질러 작동한다는 것을 보이려고 한다.
- GPT-2 small (디코더 트랜스포머). 위의 실행 예시. 59만 파라미터 Wv slice — 모델의 0.5% — 로 여섯 개의 틀린 수도를 고친다. 부작용 0, 네 가지 경로 변형 비교.
- BERT (인코더 트랜스포머). GLUE 다섯 태스크. 분리도 기반 레이어 스킵 + 작은 보상 분류기로 3/5 태스크 무손실 압축. FFN을 92% 구조적 (norm 정규화) + 8% 분류로 분해 — 개별 레이어 단위로는 분류에 해로워 보이는데도 FFN 제거가 모델을 망가뜨리는 이유가 여기 있다. 오답의 60–93%가 확신을 갖고 틀린 오답이다 — CLS 벡터 자체가 잘못된 방향을 가리킨다.
- CheXNet (의료 영상 CNN, DenseNet121). 흉부 X-ray 분류기를 정확도 유지한 채 51% 압축 (6.97M → 3.38M). 채널 단위 외과적 교정: 5채널 zero-out으로 target false positive 확률 −0.13, true positive 손실 0, 다른 13개 pathology AUROC 변화 정확히 0.
기여는 새 메커니즘이 아니다. 이미 있는 메커니즘을 사용 가능하게 만드는 파이프라인이다 — 가중치를 읽고, 각 부분이 무엇을 하는지 추적하고, 가장 작은 충분한 편집을 찾고, 부작용을 검증하고, 재현 가능한 artifact를 공개한다.
구현 단위는 다르다 — head vs. layer vs. channel. 운영 단위는 같다. 정확한 변경, 한 번의 적용, 검증 가능한 증거.
무엇이 바뀌는가
딥러닝에서 수리의 표준 모델은 더 많은 학습이다. 모델이 어긋나면 fine-tune, 정렬 문제가 생기면 align, 새 데이터가 들어오면 continually pre-train. 변경의 단위는 늘 학습 한 번이다.
외과적 편집은 다른 단위를 제안한다. 정확한 변경, 정확한 자리, 한 번의 적용, 손상 없음.
학습의 대체가 아니라 보완이다. 적용할 자리가 분명하다.
- 실패가 라우팅일 때 — 시스템에 답이 있는데 잘못된 출력이 나가는 경우 — 외과수술이 맞다.
- 실패가 진짜 부재일 때 — 시스템이 답을 가진 적 없는 경우 — 학습이 맞다.
- 실패가 정렬일 때 — 시스템의 목표가 잘못된 경우 — 외과수술은 아마 맞지 않다. 그래도 재학습을 가정하기 전에 라우팅 쪽을 먼저 의심해 볼 가치는 있다.
이 셋을 구분하는 일이 먼저다. 진단의 역할이 거기에 있다. 가중치를 읽어 각 헤드가 무얼 할 수 있는지 보고, 입력별 logit을 추적해 각 헤드가 실제로 무얼 했는지 본다. 이겨야 할 신호가 어디서 덮이는지를 짚어낸다.
이 패턴이 일반화된다면 — 정보를 보유하는 것과 전송하는 것의 구분은 어떤 스케일에서도 살아남을 만한 구분이니 — 모델 유지보수의 모습이 완전히 달라진다. *“어긋나면 재학습한다”*가 아니라 “실패를 진단하고, 그 레이어를 편집하고, 그대로 배포한다.”
다른 운영 규율이다. 정원을 가꾸기보다, 외과수술에 가깝다.
확신과 미확신
확신하는 것: GPT-2 small에서, 위에 설명한 진단 방법을 따르면, 틀렸던 여섯 개의 수도 답을 59만 파라미터 수정만으로 모두 바로잡을 수 있다. 일반 능력과 부작용 패널은 측정 노이즈 안에서 변하지 않는다. 수정된 가중치는 누구나 검증할 수 있게 공개되어 있다.
확신하지 못하는 것: 라우팅과 저장의 구분이 오늘날의 LLM에서 얼마나 넓게 적용되는지. 실세계의 실패 가운데 라우팅 실패가 차지하는 비율이 얼마나 되는지. 모델이 커질 때 편집의 크기가 얼마나 작게 유지되는지. 진단이 수천 개의 사실에 자동화로 잘 풀리는지.
이게 다음에 물어야 할 질문들이다. 첫 번째 답 — 외과수술이 가능하다는 것 — 은 이미 나왔다.
Source: paper9 — QKV Decomposition for Transformer XAI. Zenodo · HuggingFace (수정된 가중치 + 대시보드).